Parallel processing in Stat-JR
In our new release of Stat-JR we have introduced some parallel processing features to the software when using MCMC estimation. We have implemented what is sometimes called 'embarassingly parallel' processing in that we do not attempt to parallelise steps within an MCMC run but simply parallelise when running multiple chains by farming off each chain to a different processor.
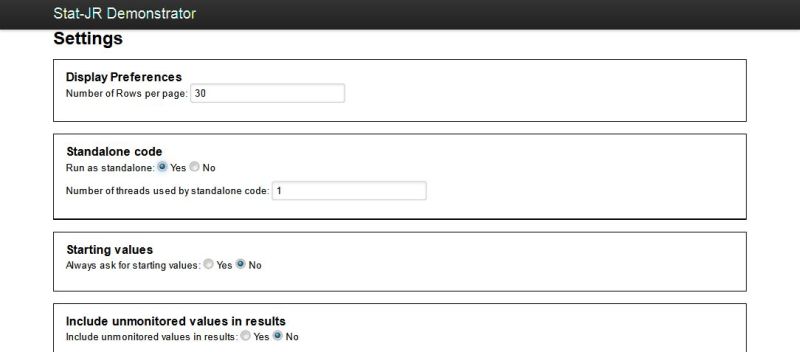
In order to notice the benefits of parallel processing we require a fairly time-consuming model fit so we will illustrate our methods using the 1LevelOrdered template although you might like to choose a different template and model to compare performance. We have currently implemented parallel processing only for the standalone C version of the software so we first need to set this up. So fire up Stat-JR and click on the Settings button. On the Settings screen click on the radio button to choose standalone code generation thus:
{kind=link}
You will notice for now that we have left the box entitled 'Number of threads used by standalone code' to 1 as we first wish to demonstrate serial running of the chains. Click on the Set button and next select 1LevelOrdered as the template and alevchem as the dataset and click on the Run button.
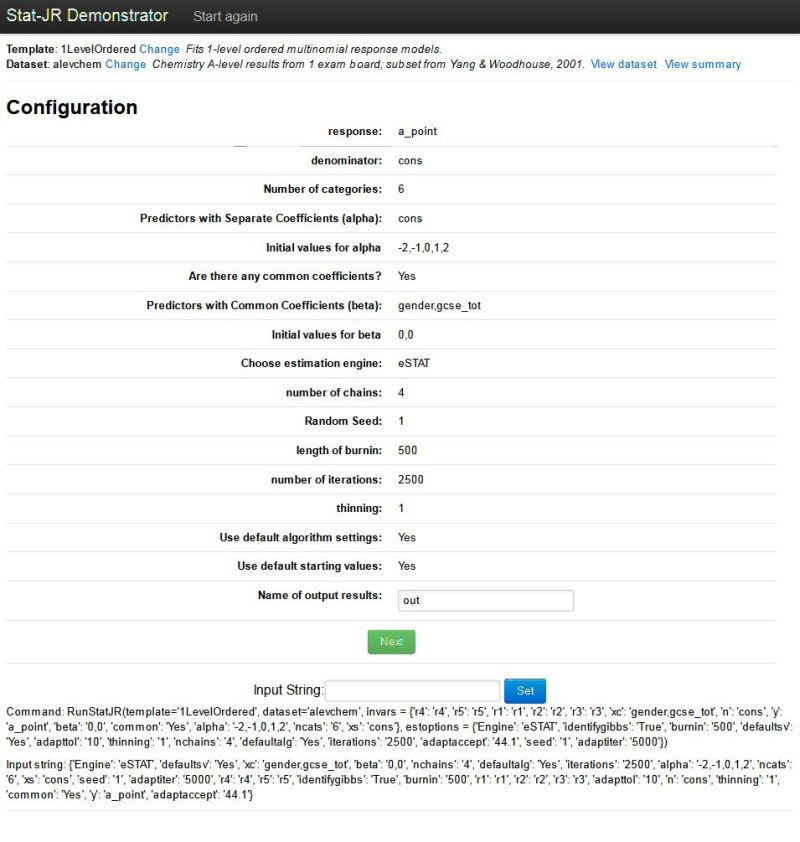
Next set up the inputs for the template as shown below:
{kind=link}
Clicking on Next will run the algebra system and set up model code. We can then press Run while timing how long the 4 chains take to run. The standalone code version of the e-Stat engine doesn't give much output while executing and so we just need to wait for it to finish. If you look at the task manager on your machine you should notice that only approximately the equivalent of 1 processor is being used (25% on my 4 processor machine) and the command window will show the following as time progresses:
adapted for 0 adapted for 0 adapted for 0 adapted for 0 Finished adapting (510 seconds) Finished burnin (625 seconds) Chain 0: starting Chain 1: starting Chain 2: starting Chain 3: starting Chain 0: finished Chain 1: finished Chain 2: finished Chain 3: finished Finished iterating (1201 seconds)
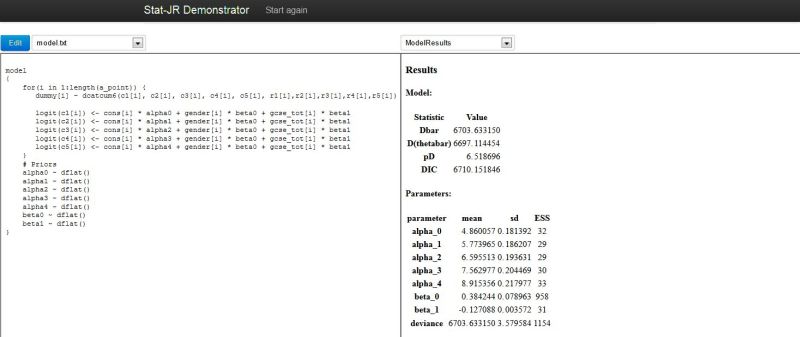
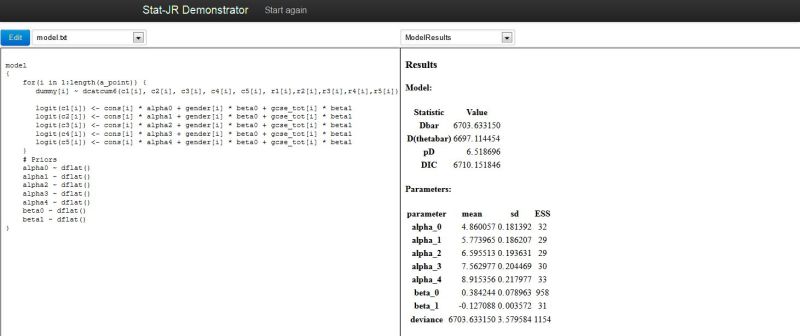
So in total it takes about 20 minutes to run this model with four chains in serial and the results are as follows:
{kind=link}
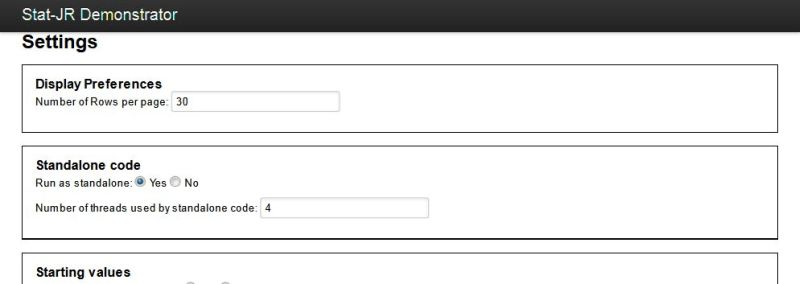
If we return to the Settings screen and change the number of threads to 4 as shown below we can then see what happens when we run in parallel:
{kind=link}
So clicking on Set and then setting up the model as before we can repeat running the model. Looking at the task manager we will see that 4 CPUs are being used and in fact on my machine which only has 4 processors it is harder to perform other tasks while execution is occurring. The command window will have the same information as shown below only this time you will note the increase in speed.
adapted for 0 adapted for 0 adapted for 0 adapted for 0 Finished adapting (148 seconds) Finished burnin (178 seconds) Chain 0: starting Chain 1: starting Chain 2: starting Chain 3: starting Chain 0: finished Chain 1: finished Chain 2: finished Chain 3: finished Finished iterating (328 seconds)
The four chains finish running in less than 6 minutes and although the time is not quite cut by four as some work is still serial (the compilation at the start and the graph creation at the end), the longer the estimation the larger the percentage saving.
{kind=link}
Back to New features.